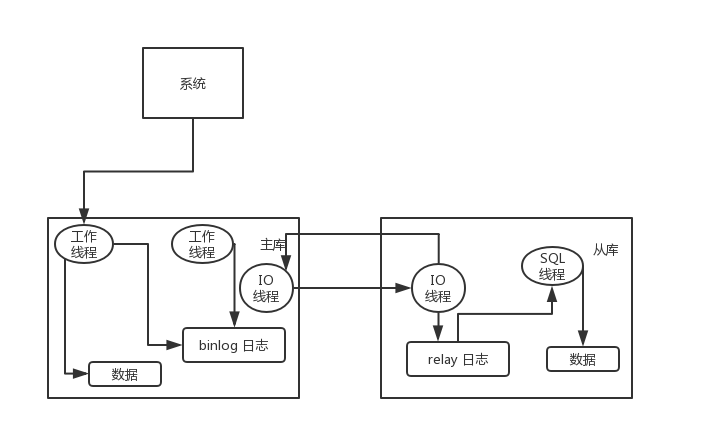
主从延迟情况
我们先看看,哪些情况会导致主从延时:
- 从库机器性能:从库机器比主库的机器性能差,只需选择主从库一样规格的机器就好。
- 从库压力大:可以搞了一主多从的架构,还可以把 binlog 接入到 Hadoop 这类系统,让它们提供查询的能力。
- 从库过多:要避免复制的从节点数量过多,从库数据一般以3-5个为宜。
- 大事务:如果一个事务执行就要 10 分钟,那么主库执行完后,给到从库执行,最后这个事务可能就会导致从库延迟 10 分钟啦。日常开发中,不要一次性 delete 太多 SQL,需要分批进行,另外大表的 DDL 语句,也会导致大事务。
- 网络延迟:优化网络,比如带宽 20M 升级到 100M。
- MySQL 版本低:低版本的 MySQL 只支持单线程复制,如果主库并发高,来不及传送到从库,就会导致延迟,可以换用更高版本的 MySQL,支持多线程复制。
![图片[1]-主从延时的原因及解决方案-编程社](https://cos.bianchengshe.com/wp-content/uploads/2023/11/image-28.png?imageMogr2/format/webp/interlace/1/quality/100)
主从延时解决方案
面试时,有些同学能回答出使用缓存、查询主库、提升机器配置等,仅仅这些么?
最容易想到的方法,缩短主从同步时间:
- 提升从库机器配置,可以和主库一样,甚至更好;
- 避免大事务;
- 搞多个从库,即一主多从,分担从库查询压力;
- 优化网络宽带;
- 选择高版本 MySQL,支持主库 binlog 多线程复制。
也可以从业务场景考虑:
- 使用缓存:我们在同步写数据库的同时,也把数据写到缓存,查询数据时,会先查询缓存,不过这种情况会带来 MySQL 和 Redis 数据一致性问题。
- 查询主库:直接查询主库,这种情况会给主库太大压力,核心场景可以使用,比如订单支付。
如果能把上面基本回答出来,就已经非常厉害了,还有么?
其实还可以在 MySQL 架构上来考虑。
主库对数据安全性较高,设置配置如下:
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1而 slave 不需要这么高的数据安全,完全可以将 sync_binlog 设置为 0,或者关闭 binlog,innodb_flushlog 也可以设置为 0,来提高 sql 的执行效率。
架构方案:使用多台 slave 来分摊读请求,再从这些 slave 中取一台专用的服务器,只作为备份用,不进行其他任何操作,比如设置 sync_binlog 为0,或者关闭 binglog 等,提升从库查询性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











暂无评论内容