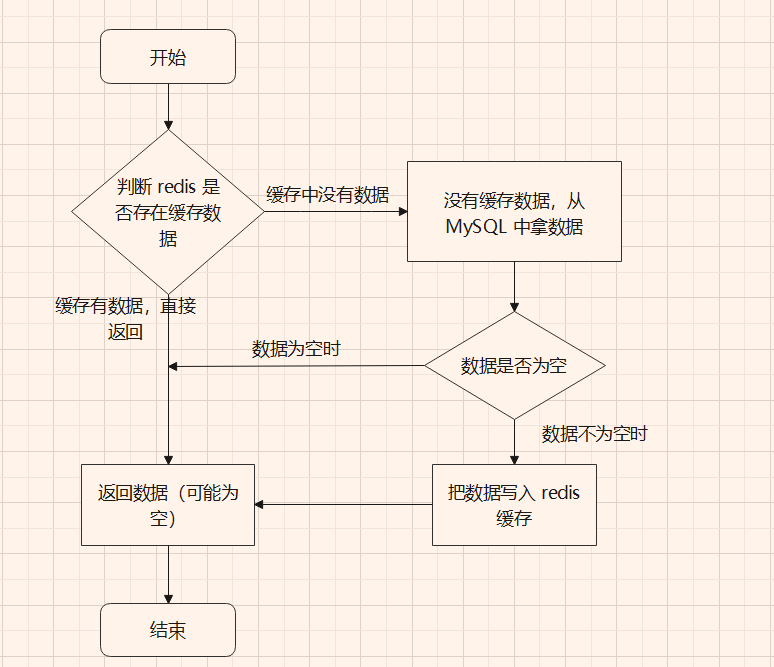
- 缓存:是 redis 被使用最多的场景之一,业务数据一般存在磁盘中,当我们要读写数据时,直接去磁盘里面访问就可以。但磁盘 IO 一直是业务性能提升的一个重要瓶颈,且并发量很高的情况下,数据库承受不了访问压力甚至还会宕机。而缓存就是为了应对这些场景产生的,当用到缓存时,先把一部分业务数据从 MySQL 写到 redis 中,用户在访问业务数据时,先到 redis 中拿数据;如果不存在,再到 MySQL 中拿,接着把访问过的数据写入 redis 中:
![图片[1]-redis常见的使用场景-编程社](https://cos.bianchengshe.com/wp-content/uploads/2023/11/image-21.png?imageMogr2/format/webp/interlace/1/quality/100)
用 redis 作缓存时,访问速度快,且 redis 提供持久化机制,可以保证服务宕机之后,缓存数据依旧可以恢复。
- 消息队列: 上篇文章中我们已经说到,Redis 中的
list数据结构可以用LinkedList双向链表实现 。它可以很轻松地实现消息队列(生产者/消费者模型)。消息的生产者只需要通过lpush命令将消息放入list,消费者可以通过rpop取出该消息,并且保证消息的有序性。
如果需要实现带有优先级的消息队列也可以选择 sorted list。
- 分布式锁:在实现了高可用的业务场景中,假设现网的某个服务运行在三台服务器上。当客户端进行业务访问时,每台服务器被访问的概率一致。这种情况下,想要控制只能由一台服务器去执行某些操作时(比如更新共享内存,防止并发),就可以用到分布式锁。简单来说,分布式锁就是为了保证多台服务器在执行某一段代码时保证只有一台服务器执行。Redis 实现分布式锁主要利用了
setnx命令,setnx 即SET if not exists(如果不存在,则 SET) 的简写:
127.0.0.1:6379> setnx lock value1 #在键lock不存在的情况下,将键key的值设置为value1
(integer) 1
127.0.0.1:6379> setnx lock value2 #试图覆盖lock的值,返回0表示失败
(integer) 0当某个客户端执行时,对某一段代码用 setnx 命令进行加锁。不存在则保存,并返回 1 表示加锁成功;如果已经存在则返回 0,加锁失败,代表该段代码已被加锁。分布式锁需要满足以下几点:
1、互斥性。在任何时刻,保证只有一个客户端持有锁。
2、不能出现死锁。如果在一个客户端持有锁的期间,这个客户端崩溃了,也要保证后续的其他客户端可以上锁。
3、保证上锁和解锁都是同一个客户端。
- 好友关系:redis 的
sinter命令可以很方便地对两个 set 取交集,所以在维护好友关系的朋友圈时,把 A 关注的人放到 A:foller 集合中,B 关注的人放到 B:foller 中。当 A 访问 B 时,就可以通过交集的方式获得 A 和 B 同时关注的好友。
- 排行榜、计数器等等
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容